Data enrichment
Enrichment skills:
- Data Categorization (Coding policies, working methods)
- Collaboration Scheme (Tool implementation, support, team coaching)
- Coding Strategies (Outsourcing, QA, SLA’s)
Original post (illustrating the Data Enrichment concept) :
The second step of elicitation is enrichment. Once your data have been patterned, you have to design their look and feel. This is what data enrichment is about.
Again key questions in this area:
- How do I qualify my data? → a categorization scheme is key to facilitate relevant data extraction for future analysis
- What may be missing or on the contrary is uselessly kept? → choosing one’s data set is necessary for correct data acquisition
- What type of addition is relevant and what is really useful? → as existing information may not be sufficient for achieving marketing studies
- How do I acquire additional attributes at an optimum price? → collect, derive or generate additional data at proper cost
No question, your data are rich, especially if you can use them easily thanks to an appropriate patterning. But they certainly can be richer. Much richer. And there are hundreds of ways to enrich data, but only two dimensions to consider, quantity and quality.
You may have tons of data, and still this may not fit your purposes. Or on the contrary have scarce resources, but with a very high (and maybe hidden) value. Market Research companies used to name this data enrichment processing « coding the dictionary », a phrase showing the richness of this process, both on the quantity (the number of words) and on the quality side (the clarity of the definitions). Getting the relevance out of the data is definitely a precious skill, and one of my own key proficiencies.
I shall definitely develop both aspects of data enrichment in future posts but I wanted to cover them shortly in this introduction.
1. Quantity
One always seems to be missing data. More e-mails for more direct marketing contacts, more socio-demographics for a better segmentation, more inputs from the sales force for a more precise CRM, more, more, more…
As usual, this may be true. Or not! Is Facebook the better source for reaching a specific population? Sure no. For instance, should you want to reach people affected by albinism in North America, you would probably rather get in touch with the NOAH. So, it depends on the purpose. And on your means to leverage a big amount of data.
Of course, I shall not dispute that a large database will give you more opportunities for reaching your targets. But better do it with the maximum level of quality. I shall then cover such topics as coverage, census vs. sample, long tail later on, as dealing with large databases is mostly a question of finding out the right data in the right timing.
2. Quality
A good quality is the heir of a proper patterning. And quality always is the key to an efficient database. The specificity of quality improvement also is that it implies all records, old and new. Unlike for quantity (adding new records is an ongoing task, you seldom look back on past data), quality always requires to give a look ahead AND behind. Adding a new feature, adjusting existing attributes to new constraints, redesigning existing concepts, all this implies a full database review.
I shall cover methods and tips for improving one’s database also in the future. Still the best piece of advice I can give is simple: think twice before starting. I have added below a simple example about the long tail of the internet.
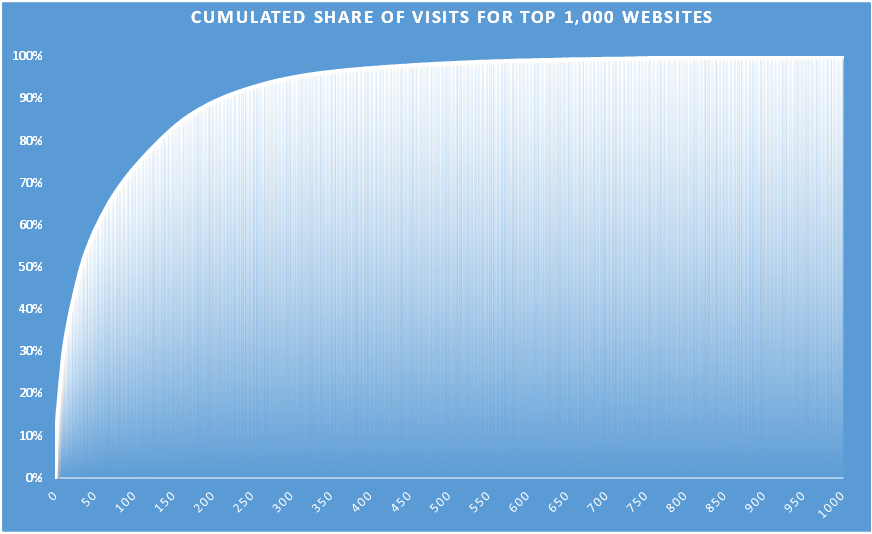
This chart shows a top 1,000 websites, ranked on their visits for a given time period, using their share of visit. The metrics itself is not interesting, rather the data distribution.
The top 50 of the websites (5% of the total records), very well-known, will allow a fair coverage of the activity, e.g. more or less 60% of the visits. So for a small set of data, with a high level of recognition, we could have a good understanding of the activity. Good for global strategy and high-level analysis.
Still, on the other hand the bottom 500 websites account for more or less 1.5% of the visits. Too costly to reach for if you are on a global strategy level, but of the highest interest if you are searching for a niche or a specific type of target audience.
There is no point in balancing between a small database of high quality, and an extra-large one with a high sparsity. Again, the point is to have the database calibrated for your needs. And then enrich it wisely. And you know it by now, I have already told you: this is exactly what Data Elicitation is about!
Laisser un commentaire